VideoDetective
Clue Hunting via both Extrinsic Query and Intrinsic Relevance for Long Video
Understanding
Introduction
VideoDetective is a plug-and-play inference framework for long-video understanding that integrates extrinsic query relevance with intrinsic video structure. By modeling the video as a Spatio-Temporal Affinity Graph, it performs an iterative Hypothesis-Verification-Refinement loop to propagate relevance signals from sparse observations to the entire video. This allows the model to "See Less but Know More", accurately localizing critical clues for complex reasoning under limited context budgets.
Framework
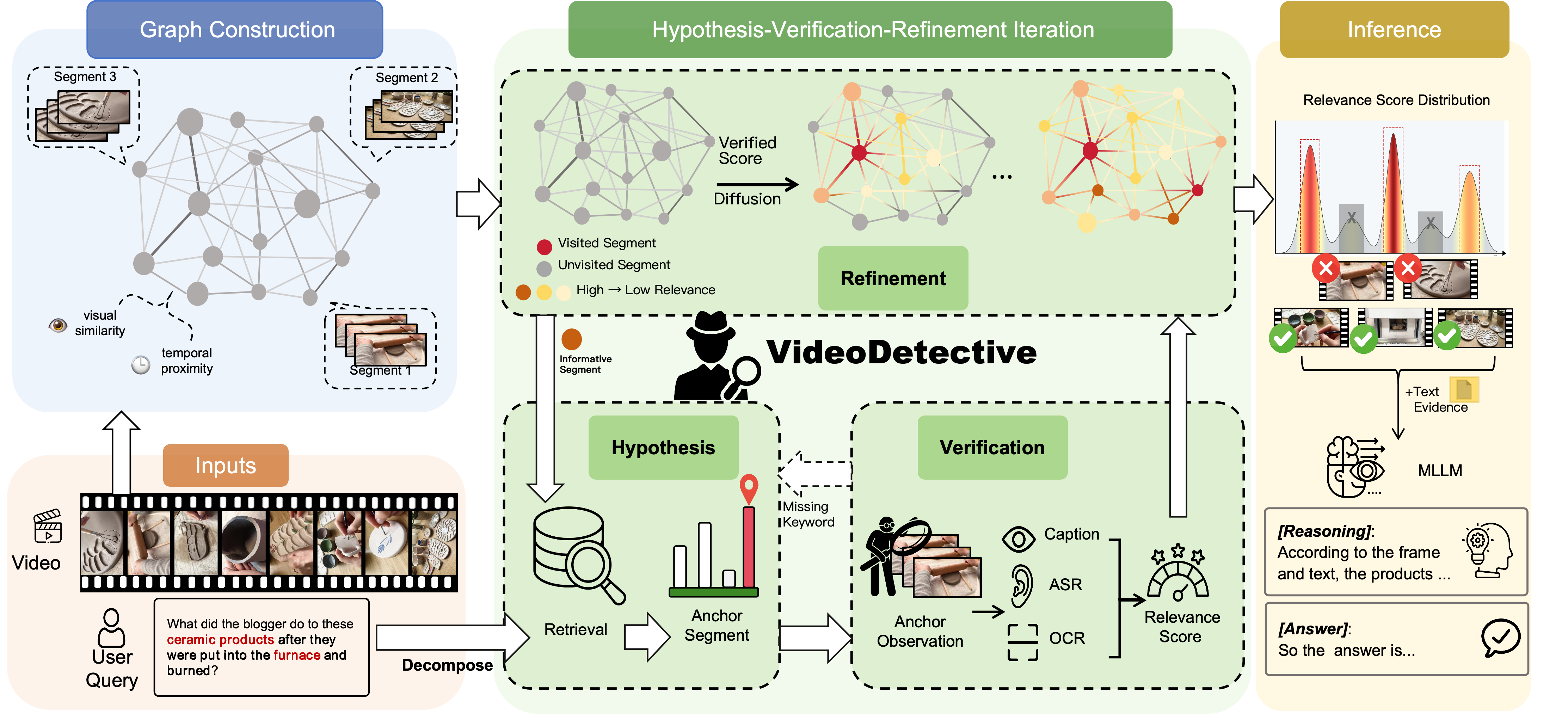
Figure 1. Overview of the VideoDetective Framework.
Given a video and a query, we (1) construct a spatio-temporal affinity graph; (2) iteratively observe sparse
segments and propagate relevance via a global belief field; (3) aggregate a compact multimodal evidence set
for the final answer.
Results
Generalization across Backbones
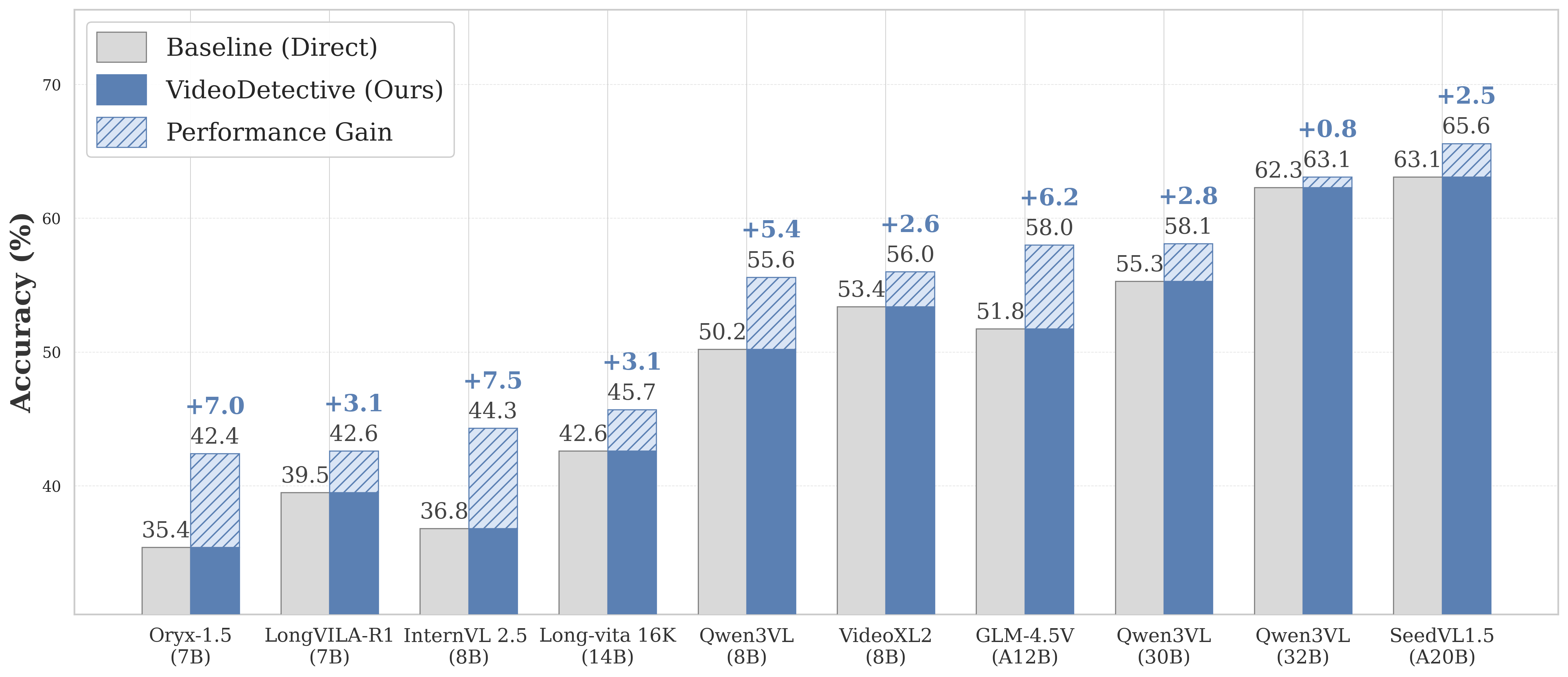
Figure 2. Performance improvements across different backbones.
VideoDetective consistently enhances various multimodal large language models (e.g., Qwen, InternVL, GLM)
across different architectures and parameter scales, demonstrating its plug-and-play capability.
Comparison with State-of-the-Art
VideoDetective achieves state-of-the-art performance across multiple long-video benchmarks.
| Model | Param | Frames | VideoMME (Long w/o sub) |
LVBench |
MLVU (Test) |
LongVideoBench (Val) |
|---|---|---|---|---|---|---|
| Proprietary Models | ||||||
| GPT-4o | - | 384 | 65.3 | 48.9 | 54.9 | 66.7 |
| Gemini-1.5-Pro | - | 256 | 67.4 | 33.1 | 53.8 | 64.0 |
| SeedVL-1.5 | 20B(A) | 32 | 63.1 | 46.1 | 54.9 | 63.8 |
| Open-Source Models (< 30B) | ||||||
| LongVITA-16k | 14B | 64 | 54.7 | - | - | 59.4 |
| LongVILA | 7B | 1fps | 53.0 | - | - | 57.1 |
| LLaVA-OneVision | 7B | - | 46.7 | - | 47.2 | 56.4 |
| LLaVA-Video | 7B | 512 | 52.9 | 43.1 | - | 58.2 |
| VideoXL | 7B | 1fps | 52.3 | 42.9 | 45.5 | 50.7 |
| Qwen2.5-VL | 7B | 128 | 53.9 | 36.9 | 45.5 | 51.0 |
| Qwen3-VL | 8B | 32 | 50.2 | 41.1 | 50.1 | 58.9 |
| InternVL-2.5 | 8B | 32 | 50.8 | 39.9 | 52.8 | 59.2 |
| VITA-1.5 | 7B | 16 | 47.1 | 37.1 | 39.4 | 53.6 |
| VideoDetective (Qwen3-VL) | 8B | 32 | 55.6 | 43.2 | 56.3 | 60.2 |
| Open-Source Models (≥ 30B) | ||||||
| Qwen2.5-VL | 72B | 128 | 64.6 | 47.4 | 53.8 | - |
| LLaVA-Video | 72B | 64 | 70.3 | 46.1 | - | 63.9 |
| VideoDetective (SeedVL-1.5) | 20B(A) | 32 | 65.6 | 51.3 | 63.8 | 67.9 |
Table 1. Performance comparison on challenging long-video benchmarks (VideoMME, LVBench, MLVU, LongVideoBench).
Qualitative Example
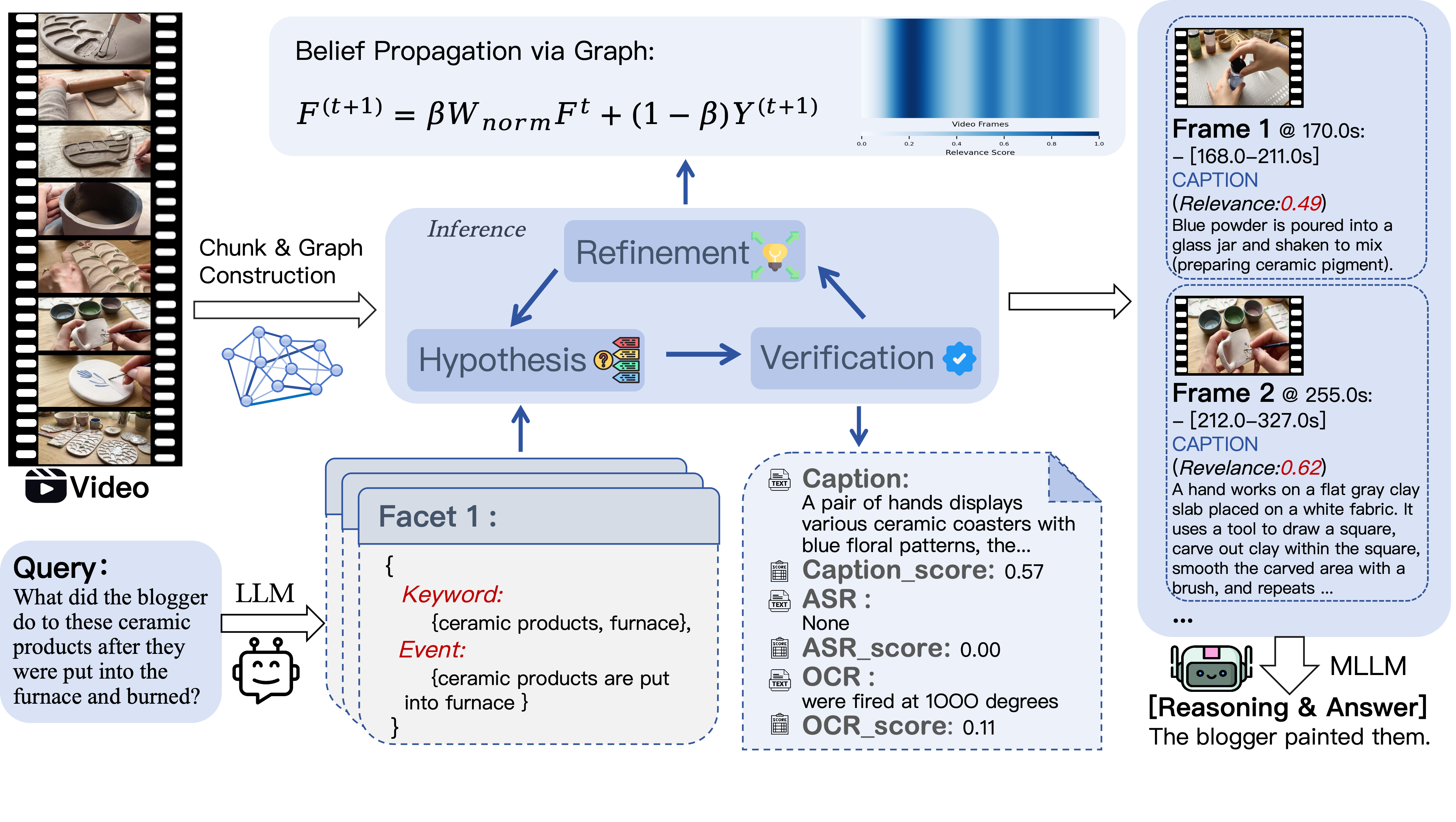
Figure 3. Active Inference Example. Original video: https://www.youtube.com/watch?v=B6tQyCH5hQM
Citation
@misc{yang2026videodetective,
title = {VideoDetective: Clue Hunting via both Extrinsic Query and Intrinsic Relevance for Long Video Understanding},
author = {Yang, Ruoliu and Wu, Chu and Shan, Caifeng and He, Ran and Fu, Chaoyou},
year = {2026}
}